
Come proteggere i dati personali? Anonimizzazione, pseudonimizzazione e cifratura a confronto
Tra i molteplici aspetti caratterizzanti la disciplina dettata dal Regolamento UE 2016/679[1] (di seguito “GDPR”), uno in particolare riveste una notevole rilevanza per le organizzazioni: le misure tecniche da attuare per garantire un’adeguata protezione dei dati personali. Il GDPR si limita a definire nel disposto dell’art. 32[2] alcuni punti cardine per garantire la sicurezza dei trattamenti, ma viene lasciata ai titolari e ai responsabili del trattamento una certa libertà di scelta in merito agli accorgimenti tecnici specifici da impiegare. Questa libertà di azione ha creato non poca confusione nella definizione dei limiti entro cui operare ed entro cui le disposizioni del GDPR possono essere applicate. I dubbi nascono dalla compresenza di tre diverse soluzioni tecniche, molto spesso confuse tra loro e che, quindi, alimentano il disordine interpretativo in materia: l’anonimizzazione, la pseudonimizzazione e la cifratura. Queste tre soluzioni definiscono il contesto entro cui districarsi per garantire un’adeguata e concreta protezione dei dati personali[3].
L’anonimizzazione
Per anonimizzazione si intende una tecnica che viene applicata ai dati personali in modo tale che le persone fisiche interessate non possano più essere identificate in nessun modo: l’obiettivo è ottenere una de-identificazione irreversibile[4]. De-identificare significa eliminare la correlazione tra i dati personali e una determinata persona fisica interessata, rendendo impossibile l’identificazione della stessa. Nel momento in cui i dati personali riferiti ad un individuo sono stati adeguatamente anonimizzati, dovrebbe essere impossibile poter invertire il processo, che risulta quindi irreversibile. Requisito fondamentale è che i dati personali siano stati inizialmente raccolti, trattati e conservati in conformità alla normativa vigente[5], con riferimento ai principi applicabili al trattamento e alla liceità dello stesso, ai sensi degli artt. 5 e 6 del GDPR[6].
Se l’anonimizzazione è andata a buon fine, i dati oggetto dell’operazione non sono più classificati come dati personali[7] e quindi non rientrano nella dimensione applicativa del GDPR. A sostegno di ciò, il Considerando 26 del GDPR[8] specifica che “è auspicabile applicare i principi di protezione dei dati a tutte le informazioni relative a una persona fisica identificata o identificabile. […] I principi di protezione dei dati non dovrebbero pertanto applicarsi a informazioni anonime, vale a dire informazioni che non si riferiscono a una persona fisica identificata o identificabile o a dati personali resi sufficientemente anonimi da impedire o da non consentire più l’identificazione dell’interessato”. Da ricordare, inoltre, che i dati anonimizzati sono compresi fra gli esempi specifici di “dati non personali”, così come definito nel Considerando 9 del “Regolamento UE 2018/1807 relativo alla libera circolazione dei dati non personali nell’Unione Europea”[9].
L’anonimizzazione è uno strumento prezioso che consente la condivisione di set di dati, garantendo sia la privacy delle persone fisiche[10] che la possibilità di sfruttare il predetto set di dati per analisi e ricerche statistiche. L’anonimizzazione si può realizzare tramite la rimozione, la sostituzione, la distorsione, la generalizzazione o l’aggregazione degli identificatori diretti, come il nome completo o altre caratteristiche rilevanti della persona fisica, e indiretti, cioè attributi che combinati con altre informazioni disponibili rendono identificabile una persona, come per esempio una combinazione di occupazione, stipendio ed età[11].
Uno dei metodi più comuni per anonimizzare dei dati comporta l’eliminazione degli identificatori diretti[12]. Questa singola operazione non è però sufficiente a garantire che l’identificazione della persona interessata non sia più possibile[13]. Per questo si consiglia di non utilizzare un’unica tecnica di anonimizzazione, ma una combinazione di esse. All’eliminazione degli identificatori diretti si può aggiungere a titolo esemplificativo la tecnica della generalizzazione, la quale comporta la riduzione del grado di dettaglio di una determinata variabile. Per esempio, le date di nascita di singole persone fisiche possono essere generalizzate per mese o anno, producendo una riduzione del grado di identificabilità[14]. Quindi, eliminare i nomi completi degli individui, mantenendo solo l’anno di nascita degli stessi, permette di de-identificare in modo irreversibile le persone fisiche, potendo comunque effettuare analisi statistiche sul campione di dati (Figura 1).

Figura 1: esempio di tecniche di anonimizzazione.
La pseudonimizzazione
La pseudonimizzazione è definita, nel disposto dell’art. 4 Punto 5 del GDPR[15], come “il trattamento dei dati personali in modo tale che i dati personali non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive […]”.
In concreto, questa operazione sostituisce alcuni identificatori con pseudonimi (o token, letteralmente “simbolo” o “simbolico”), cioè dati realistici, ma non veritieri. I dati originali, vengono conservati in un database separato costituito da una tabella delle corrispondenze tra dati originali e gli pseudonimi utilizzati[16]. Tutto ciò permette di re-identificare le persone fisiche, in quanto il titolare, o il responsabile del trattamento, possiede le “informazioni aggiuntive” per poter risalire all’identità degli interessati: si parla perciò di un processo reversibile.
I dati pseudonimizzati non possono essere attribuiti ad un individuo senza utilizzare le predette “informazioni aggiuntive”, che in questo caso sono rappresentate dalla tabella delle corrispondenze tra pseudonimi e dati originali. Importante ricordare che le “informazioni aggiuntive” devono essere conservate in un database separato e adeguatamente protetto. Infatti, in questo modo anche se il set di dati pseudonimizzati venisse compromesso, non sarà comunque possibile risalire ai dati originali.
La pseudonimizzazione riduce il rischio di identificazione diretta degli individui, riducendo la correlabilità di un insieme di dati all’identità originaria di una persona interessata, ma non produce dati anonimi[17]. Quindi, i dati pseudonimizzati sono dati personali e rientrano di conseguenza nella disciplina del GDPR. Infatti, il Considerando 26 del GDPR[18] chiarisce eventuali dubbi dichiarando che “i dati personali sottoposti a pseudonimizzazione, i quali potrebbero essere attribuiti a una persona fisica mediante l’utilizzo di ulteriori informazioni, dovrebbero essere considerati informazioni su una persona fisica identificabile”.
Chiarito che la pseudonimizzazione non è un metodo di anonimizzazione[19], è opportuno ricordare che l’art. 32 comma 1 lett. a) del GDPR[20] cita questa misura tecnica (insieme alla cifratura, oggetto di trattazione nel paragrafo successivo), definendola appropriata “per garantire un livello di sicurezza adeguato al rischio”. Il Considerando 28 del GDPR[21] è esplicativo in tal senso, in quanto motiva l’enfasi mostrata dal legislatore europeo verso questa specifica misura di sicurezza, affermando che “l’applicazione della pseudonimizzazione ai dati personali può ridurre i rischi per gli interessati e aiutare i titolari del trattamento e i responsabili del trattamento a rispettare i loro obblighi di protezione dei dati”. La pseudonimizzazione è, inoltre, la misura tecnica consigliata dal legislatore europeo nel disposto dell’art. 25 del GDPR[22] per rispettare il principio della privacy by design, nuovo e innovativo approccio che deve essere seguito ogniqualvolta sia necessario garantire la protezione dei dati personali[23].
La pseudonimizzazione è uno strumento fondamentale per proteggere i dati personali, ma perché viene scelta questa tecnica rispetto all’anonimizzazione? Di fatto, il principale vantaggio offerto dalla pseudonimizzazione è proprio quello di poter risalire ai dati originali avendo comunque la possibilità di divulgare i dati pseudonimizzati senza rischio di re-identificazione. Questa possibilità ha molteplici risvolti applicativi.
Si pensi, per esempio, ad una società di trasporti che elabora i dati relativi al chilometraggio, ai viaggi e alla frequenza di guida dei propri conducenti. Il trattamento dei predetti dati è funzionale all’elaborazione delle richieste di rimborso spese per i chilometri percorsi e per addebitare il costo del sevizio ai clienti. Per queste due finalità è fondamentale identificare i singoli conducenti. Tuttavia, un secondo team all’interno dell’azienda di trasporti utilizza i predetti dati per ottimizzare l’efficienza della flotta di corrieri. Per questa finalità non occorre identificare i singoli conducenti. Pertanto, l’azienda garantisce che il secondo team possa accedere ai dati solo in una forma che non consenta di identificare i singoli corrieri, sostituendo gli identificatori (nomi, etc.) con un equivalente identificativo ma fittizio. Il secondo team può accedere solo al set di dati pseudonimizzato. Nonostante ciò, l’organizzazione stessa può comunque identificare i conducenti, per adempiere alle finalità sopra descritte, grazie ad una tabella delle corrispondenze tra i dati originali e l’identificativo fittizio[24]. Nell’immagine sottostante (Figura 2) è possibile osservare l’operazione per risalire ai dati originali a partire dai dati pseudonimizzati.

Figura 2: risalire ai dati originali da dati pseudonimizzati.
Nell’esempio in Figura 2 gli pseudonimi sono rappresentati da alcuni numeri (054 e 062) che sono associati agli identificatori originali. Esistono comunque diversi metodi per generare pseudonimi, tra i quali il più comune è l’utilizzo delle funzioni di hash (letteralmente “sminuzzare”), che calcolano, a partire da un insieme di caratteri di lunghezza arbitraria, una stringa alfanumerica di lunghezza determinata[25]. Per quanto l’hash sia una funzione non invertibile (quindi non si può ritornare ai dati originali applicando una funzione inversa di hash), l’utilizzo di una tabella hash (di fatto una tabella delle corrispondenze) rende questa tecnica un’utile metodo a servizio della pseudonimizzazione: infatti, grazie alla predetta tabella la stringa alfanumerica risultante viene associata ai dati originali rendendo possibile la re-identificazione degli interessati.
La cifratura o crittografia
Il già citato Considerando 28 del GDPR specifica che “l’introduzione esplicita della «pseudonimizzazione» nel presente regolamento non è quindi intesa a precludere altre misure di protezione dei dati”, concedendo in questo modo una certa libertà di scelta ai titolari e ai responsabili del trattamento. Il legislatore ha comunque stimolato l’applicazione di ulteriori soluzioni di sicurezza indicando nell’art. 32 comma 1 lett. a) del GDPR[26], insieme alla pseudonimizzazione, la cifratura, o crittografia[27] dei dati. Questa è una fondamentale misura tecnica di sicurezza che, attraverso un apposito algoritmo matematico, rende illeggibili i dati personali a chiunque non abbia l’autorizzazione a visionarli[28], proteggendo i dati da trattamenti non autorizzati o illegali. Per accedere ai dati personali crittografati è necessario essere in possesso di una chiave di decriptazione; questa caratteristica rende la crittografia un’operazione reversibile.
In quanto operazione reversibile, anche in questo caso si applica la disciplina del GDPR: infatti, i dati cifrati sono dati personali, perché l’operazione di decifratura li rende riconducibili agli interessati, permettendone l’identificazione.
La principale differenza che intercorre tra la crittografia e la pseudonimizzazione riguarda l’accessibilità dei dati. Per quanto riguarda la pseudonimizzazione, i dati sono potenzialmente visionabili da chiunque, in quanto vengono resi disponibili per determinate finalità (per esempio, ricerca o analisi), e, quindi, oscurati solo in parte. La crittografia, invece, ha lo scopo di oscurare completamente i dati in modo che solo specifici soggetti autorizzati possano visionarli.
Per comprendere al meglio la questione, si consideri che esistono due principali metodi di crittografia:
- la crittografia simmetrica, o crittografia a chiave simmetrica (symmetric-key cryptography)[29], che utilizza una sola chiave privata sia per cifrare che per decifrare i dati[30].
- la crittografia asimmetrica, o crittografia a chiave asimmetrica (asymmetric-key cryptography)[31], che utilizza due chiavi, una pubblica ed una privata; la prima viene utilizzata per cifrare, la seconda per decifrare[32].
Nell’ipotesi in cui venga utilizzata la crittografia simmetrica, le parti utilizzano un’unica chiave per cifrare e successivamente decifrare i dati (Figura 3). Il livello di sicurezza dei dati crittografati dipende dalla gestione, conservazione e trasporto della chiave, che spesso non può essere trasmessa in totale sicurezza.

Figura 3: funzionamento della crittografia simmetrica.
La crittografia asimmetrica, invece, si fonda sull’utilizzo di due differenti chiavi:
- la chiave privata, che decifra i dati e viene mantenuta segreta;
- la chiave pubblica, che cifra i dati e viene, invece, distribuita.
La più comune implementazione di questa tecnica crittografica è la End-to-End Encryption[33] (E2EE, letteralmente, crittografia da un estremo all’altro), conosciuta prevalentemente grazie a WhatsApp, che l’ha implementata nel proprio servizio di messaggistica istantanea nel 2016[34].
Si considerino due ipotetici interlocutori, Alice e Paolo. L’applicazione fornisce a ciascuno di essi due chiavi, una pubblica e una privata. Quando Paolo desidera inviare un messaggio ad Alice, viene utilizzata la coppia di chiavi appartenenti ad Alice. La chiave privata di Alice non abbandona mai il suo smartphone e neppure il server di WhatsApp ne può venire a conoscenza. La chiave pubblica di Alice invece viene condivisa dal suo dispositivo con il server di WhatsApp, il quale la rende disponibile a chiunque desideri inviarle un messaggio. Nel momento in cui Paolo scrive un messaggio ad Alice, l’applicazione sullo smartphone di Paolo recupera la chiave pubblica di Alice, che viene usata per cifrare il messaggio. Il messaggio cifrato viene quindi inviato ad Alice. Quando il messaggio viene ricevuto, Alice utilizza la propria chiave privata per decifrare il messaggio inviato da Paolo[35] (Figura 4).
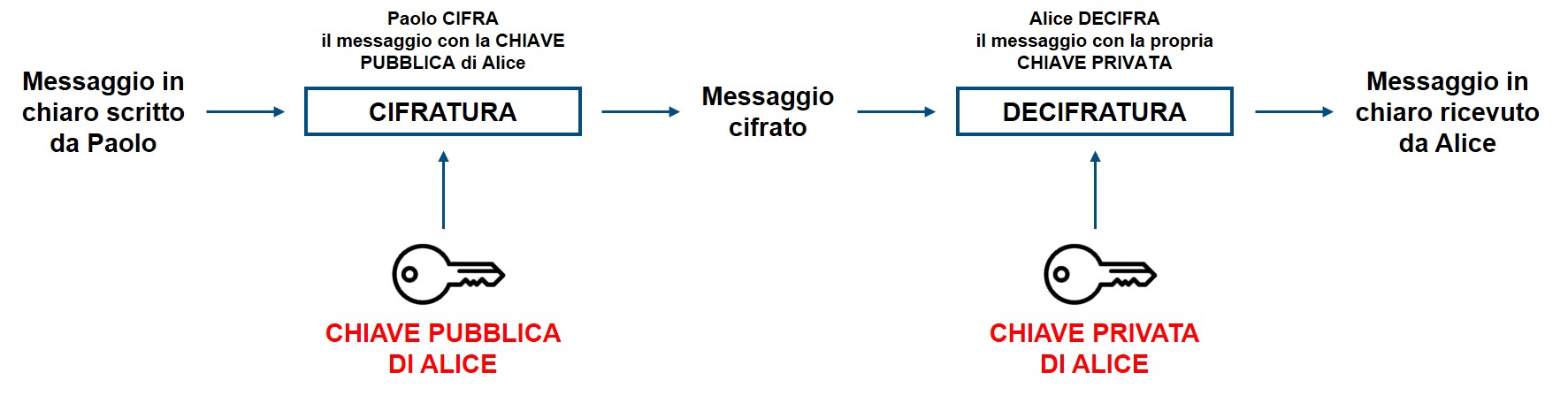
Figura 4: esempio di End-to-End Encryption.
Se, al contrario, è Alice che desidera inviare un messaggio a Paolo, viene utilizzata la coppia di chiavi appartenenti a Paolo e si realizza lo scambio appena descritto a parti invertite.
Considerazioni e conclusioni
Distinguere tra anonimizzazione, pseudonimizzazione e cifratura dei dati è un primo importante passo per esercitare una corretta ed efficiente protezione dei dati personali. Per quanto le tre categorie di soluzioni di sicurezza risultino distinte, la scelta ottimale è comunque quella di utilizzare una composizione di più tecniche. Per esempio, considerando quanto espresso nei precedenti paragrafi, dopo aver applicato una misura per pseudonimizzare un set di dati, potrebbe essere efficace proteggere le “informazioni aggiuntive” contenute nella tabella delle corrispondenze applicando una tecnica crittografica, in modo da ridurre il rischio di accessi non autorizzati alle informazioni fondamentali per identificare gli interessati.
Per risultare conformi al GDPR è opportuno comprendere a pieno e a fondo il panorama delle misure tecniche di sicurezza, così da garantire un’adeguata protezione dei dati personali a tutela degli interessati. Inoltre, approfondire un aspetto così specifico e tecnico garantisce uno studio concreto e pratico della normativa di riferimento, evitando un approccio eccessivamente accademico che talvolta si dimostra particolarmente limitante.
[1] Regolamento (UE) n. 2016/679 relativo alla protezione delle persone fisiche con riguardo al trattamento dei dati personali, nonché alla libera circolazione di tali dati, qui consultabile:
[2] G. Cavallari, La sicurezza del trattamento: analisi dell’articolo 32 GDPR, gennaio 2019, https://www.iusinitinere.it/la-sicurezza-del-trattamento-analisi-dellarticolo-32-gdpr-16205
[3] Le figure esplicative proposte nell’articolo sono prodotte dall’autore.
[4] Gruppo di lavoro articolo 29, Parere 05/2014 sulle tecniche di anonimizzazione, p. 7, qui consultabile: https://ronchilegal.eu/wp-content/uploads/2017/12/Anonimizzazione-secondo-il-WP29-del-2014_it-1.pdf
[5] Ibid, p. 7.
[6] V. supra n. 1, art. 5 e 6.
[7] D. Whitelegg, Minimizing application privacy risk, maggio 2018, https://developer.ibm.com/articles/s-gdpr3/
[8] V. supra n. 1, Considerando 26.
[9] Regolamento (UE) 2018/1807 relativo a un quadro applicabile alla libera circolazione dei dati non personali nell’Unione europea, qui consultabile: https://eur-lex.europa.eu/legal-content/IT/TXT/PDF/?uri=CELEX:32018R1807&from=EN
[10] UK Data Service, Anonymisation, https://www.ukdataservice.ac.uk/manage-data/legal-ethical/anonymisation/qualitative.aspx
[11] Ibid.
[12] Ibid.
[13] V. supra n. 4, p. 10.
[14] Ibid, p. 18.
[15] V. supra n. 1, art. 4.
[16] V. supra n. 7.
[17] M. Mourby, E. Mackey, M. Elliot, H. Gowans, S.E. Wallace, J. Bell, H. Smith, S. Aidinlis e J. Kaye, Are ‘pseudonymised’ data always personal data? Implications of the GDPR for administrative data research in the UK, in S. Stalla-Bourdillon (a cura di), Computer Law and Security Review, 2018, Vol. 34, No. 2, p. 223.
[18] V. supra n. 1, Considerando 26.
[19] V. supra n. 4, p. 3.
[20] V. supra n. 1, art. 32.
[21] V. supra n. 1, Considerando 28.
[22] V. supra n. 1, art. 25.
[23] N. Fabiano, Privacy by Design: l’approccio corretto alla protezione dei dati personali, Diritto24, http://www.diritto24.ilsole24ore.com/art/dirittoCivile/2015-04-20/privacy-by-desi-gn-approccio-corretto-protezione-dati-personali-123915.php
[24] Information Commissioner’s Office, What is personal data?, https://ico.org.uk/for-organisations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/what-is-personal-data/what-is-personal-data/
[25] Tra gli algoritmi di hash il più noto è SHA (Secure Hash Algorithm). Con il termine SHA si indica una famiglia di cinque diverse funzioni crittografiche di hash (SHA-1, SHA-224, SHA-256, SHA-384 e SHA-512) sviluppate a partire dal 1993 dalla National Security Agency (NSA) e pubblicate dal National Institute of Standards and Technology (NIST) come standard federale degli Stati Uniti. La differenza tra le cinque diverse funzioni è rappresentata dalla dimensione dell’output. Le funzioni producono una stringa di lunghezza in bit pari al numero indicato nella loro sigla. L’unica funzione che differisce nel nome è SHA-1 che non produce un output di 1 bit, ma di 160 bit. Di seguito un esempio di applicazione di una funzione di hash (in questo caso la SHA-1) al nome Davide e al nome Ius in itinere, effettuata grazie ad un generatore online (qui disponibile, https://passwordsgenerator.net/sha1-hash-generator/); si noti come la stringa alfanumerica restituita è sempre della stessa lunghezza (40 caratteri esadecimali), indipendentemente dalla dimensione dell’input:
- Davide >> 302FE5BC653E0F2B2E93B6F56C89D0AAB0F04BB3
- Ius in itinere >> BA13429CAF0AF78373361133E678218153E1FE52
Per un ulteriore approfondimento: A. Rolleri, Algoritmi Hash, http://alessiorolleri.wikidot.com/algoritmi-hash
[26] V. supra n. 1, art. 32.
[27] Uno dei più antichi algoritmi crittografici di cui si abbia traccia storica è il cifrario di Cesare. Si tratta di un cifrario a sostituzione monoalfabetica in cui ogni lettera del testo in chiaro è sostituita nel testo cifrato dalla lettera che si trova un certo numero di posizioni dopo nell’alfabeto. Questi tipi di cifrari sono detti anche cifrari a sostituzione o cifrari a scorrimento, a causa del loro modo di operare: la sostituzione avviene lettera per lettera, scorrendo il testo dall’inizio alla fine. Il cifrario di Cesare prende il nome da Giulio Cesare, che lo utilizzava per proteggere i suoi messaggi segreti. Grazie all’opera storiografica Vite dei Cesari di Svetonio sappiamo che Cesare utilizzava in genere una chiave di tre per il cifrario (cioè sostituire una lettera con quella che si trova tre posizioni dopo), come nel caso della corrispondenza militare inviata alle truppe comandate da Quinto Tullio Cicerone. Al tempo era un metodo sicuro perché gli avversari spesso non erano in grado di leggere un testo in chiaro, men che mai uno cifrato; inoltre non esistevano metodi di crittanalisi in grado di rompere tale codice, per quanto banale.
Per approfondire ulteriormente: Wikipedia, Cifrario di Cesare, https://it.wikipedia.org/wiki/Cifrario_di_Cesare
[28] G. Spindler e P. Schmechel, Personal Data and Encryption in the European General Data Protection Regulation, in Journal of Intellectual Property, Information Technology and E-Commerce Law, 2016, Vol. 7, p. 169, §32.
[29] IBM Knowledge Center, Symmetric cryptography, https://www.ibm.com/sup-port/knowledgecenter/en/SSB23S_1.1.0.15/gtps7/s7symm.html
[30] La crittografia simmetrica utilizza diversi algoritmi e tra questi i più famosi sono il DES (Data Encryption Standard) e l’AES (Advanced Encryption Standard). Per approfondire:
- DES: A. Rolleri, Data Encryption Standard, http://alessiorolleri.wikidot.com/crypto-des
- AES: A. Rolleri, Algoritmo AES, http://alessiorolleri.wikidot.com/crypto-aes
[31] IBM Knowledge Center, Public key cryptography https://www.ib-m.com/support/knowledgecenter/en/SSB23S_1.1.0.15/gtps7/s7pkey.html
[32] La crittografia asimmetrica utilizza, tra gli altri, un algoritmo denominato RSA, che trae il nome dalle iniziali dei suoi tre inventori: Rivest, Shamir e Adleman. Per approfondire: A. Rolleri, Algoritmo RSA, http://alessiorolleri.wikidot.com/crypto-rsa
[33] V. supra n. 28, p. 175, §70.
[34] WhatsApp – Sicurezza e privacy, Crittografia End-to-End, https://faq.whats-app.com/it/android/28030015/
[35] ChatMap, End-to-End Encryption Explained – Infographic,
Ho conseguito la laurea triennale in Scienze dei servizi giuridici nel 2016, presso l’Università Statale di Milano, con una tesi sul GDPR e il Privacy Shield. In seguito, ho concluso il mio percorso universitario nel 2018, conseguendo la laurea magistrale in Management e design dei servizi, presso l’Università di Milano Bicocca, con una tesi sul metodo Lego® Serious Play®. Un percorso un po’ inusuale, ma davvero utile per poter applicare un approccio multidisciplinare a ciò di cui sono appassionato: la protezione dei dati personali.
Da ottobre 2018 a settembre 2019 mi sono occupato di conformità al GDPR in Logotel, una società che si occupa di service design, formazione e di creazione e gestione di business community per clienti corporate.
Da settembre 2019 lavoro come Legal Consultant, occupandomi di protezione dei dati personali nella società di consulenza Partners4Innovation. Nello specifico mi occupo di progetti data protection in diverse organizzazioni, sia private che pubbliche.
Nell’area IP & IT di Ius in Itinere scrivo di protezione dei dati personali e privacy, con il desiderio di approfondire ancora di più queste tematiche e di fornire interessanti spunti ai lettori.


